
高质量程序设计指南(第三版.林悦编著).md 53 KB
通过渐构方法进行拆书
遵照书中的掌机顺序进行拆分,会删除部分无用描述
词典的定义是:
① 典型的或本质的特征;
② 事物固有的或区别于其他事物的特征或本质;
③ 优良或出色的程度。
CMM对质量的定义是:
① 一个系统、组件或过程符合特定需求的程度;
② 一个系统、组件或过程符合客户或用户的要求或期望的程度。
早先人们以为长得结实、饭量大就是健康,这显然是不科学的。
现代人总是通过考察多方面的生理因素来判断是否健康,如测量身高、体重、心跳、血压、血液、体温等。
如果上述因素都合格,那么表明这人是健康的。
如果某个因素不合格,则表明此人在某个方面不健康,医生会对症下药。
同理,我们也可以通过考察软件的质量属性来评价软件的质量,并给出提高软件质量的方法。
一提起软件的质量属性,
人们首先想到的是“正确性”。“正确性”的确很重要,但运行正确的软件就是高质量的软件吗?
不见得,因为这个软件也许运行速度很低,并且浪费内存,甚至代码写得一塌糊涂,
除了开发者本人谁也看不懂,也不会使用。可见正确性只是反映软件质量的一个因素而已。
软件质量的评判标准所使用的新词可谓层出不穷。
如正确性、
精确性,
健壮性、
可靠性、
容错性、
性能、
易用性、
安全性、
可扩展性、
可复用性、
兼容性、
可移植性、
可测试性、
可维护性、
灵活性等。
除此之外还可以列出十几个
上述这些质量属性“你中有我,我中有他”。
如果开发人员每天都要面对那么多的质量属性咬文嚼字,不久就会迂腐得像孔乙己,
因此我们有必要对质量属性做些分类和整合。
质量属性可分为两大类:“功能性”与“非功能性”,后者有时也称为“能力”(Capability)。
功能性质量属性有3个:
正确性、健壮性和可靠性;
非功能性质量属性有7个:
性能、易用性、清晰性、安全性、可扩展性、兼容性和可移植性。
为什么碰巧是“10大”呢?
不为什么,只是方便记忆而已(如同国际、国内经常评“10大”那样)。
为什么“10大”里面不包括
可测试性、
可维护性、
灵活性、
它们不也是很重要的吗?
它们是很重要,但不是软件产品的卖点,所以挤不进“10大”行列。
我认为如果做好了上述“10大”质量属性,软件将会自然而然地具备良好的可测试性、可维护性。
人们很少纯粹地去提高可测试性和可维护性,勿要颠倒因果。
至于灵活性,它有益处也有坏处,
该灵活的地方已经被其他属性覆盖,而不该灵活的地方就不要刻意去追求。
根据经验,如果你想一股脑儿地把任何事情都做好,
结果通常是什么都做不好,做事总是要分主次的。
什么是重要的质量属性,应当视具体产品的特征和应用环境而定,请读者不要受本书观点的限制。
最简单的判别方式就是考察该质量属性是否被用户关注(即卖点)。
正确性是指软件按照需求正确执行任务的能力。
这里“正确性”的语义涵盖了“精确性”。
正确性无疑是第一重要的软件质量属性。
如果软件运行不正确,将会给用户造成不便甚至损失。
技术评审和测试的第一关都是检查工作成果的正确性。
正确性说起来容易做起来难。
因为从“需求开发”到“系统设计”再到“实现”,任何一个环节出现差错都会降低正确性。
机器不会主动欺骗人,软件运行出错通常都是人造成的,所以不要找借口埋怨机器有毛病。
开发任何软件,开发者都要为“正确”两字竭尽全力。
健壮性是指在异常情况下,软件能够正常运行的能力。
正确性描述软件在需求范围之内的行为,
健壮性描述软件在需求范围之外的行为。
可是正常情况与异常情况并不容易区分,
开发者往往要么没想到异常情况,
要么把异常情况错当成正常情况而不做处理,结果降低了健壮性。
用户才不管正确性与健壮性的区别,反正软件出了差错都是开发方的错。
所以提高软件的健壮性也是开发者的义务。
一是容错能力,二是恢复能力。
容错是指发生异常情况时系统不出错误的能力
对于应用于航空航天、武器、金融等领域的这类高风险系统,容错设计非常重要。
容错是非常健壮的意思,比如UNIX的容错能力很强,很难使系统出问题。
而恢复则是指软件发生错误后(不论死活)重新运行时,能否恢复到没有发生错误前的状态的能力。
例如,某人挨了坏蛋一顿拳脚,
特别健壮的人一点事都没有,表示有容错能力;
比较健壮的人,虽然被打倒在地,
过了一会还能爬起来,除了皮肉之痛外倒也不用去医院,
表示恢复能力比较强;
而虚弱的人可能短期恢复不过来,得在病床上躺很久。
Microsoft公司早期的窗口系统,如Windows 3.x和Windows 9x,动不动就死机,
其容错性的确比较差。
但它们的恢复能力还不错,
机器重新启动后一般都能正常运行,看在这个份上,
人们也愿意将就着用。
可靠性不同于正确性和健壮性,
软件可靠性问题通常是由于设计中没有料到的异常和测试中没有暴露的代码缺陷引起的。
可靠性是一个与时间相关的属性,
指的是在一定环境下,在一定的时间段内,
程序不出现故障的概率,因此是一个统计量,
通常用平均无故障时间(MTTF, mean-time to fault)来衡量。
可靠性本来是硬件领域的术语。
比如某个电子设备在刚开始工作时挺好的,
但由于器件在工作中其物理性质会发生变化(如发热、老化等),
慢慢地系统的功能或性能就会失常。
所以一个从设计到生产完全正确的硬件系统,在工作中未必就是可靠的。
人们有时把可靠性叫做稳定性。
软件在运行时不会发生物理性质的变化,
人们常认为如果软件的某个功能是正确的,
那么它一辈子都是正确的。
可是我们无法对软件进行彻底的测试,无法根除软件中潜在的错误。
平时软件运行得好好的,
说不准哪一天就不正常了,因此把可靠性引入软件领域是很有意义的。
原书未提及,自行了解
导致内存耗尽,系统崩溃。
导致计算错误进而导致连锁反应
遗憾的是目前可供第一线开发人员使用的成果很少见,
大多数文章限于理论研究。我曾买了一本关于软件可靠性的著作,
此书充满了数学公式,实在难以看懂,更不知道怎样应用。
请宽恕我的愚昧,我把此“天书”给“供养”起来,没敢用笔画一处记号。
口语中的可靠性含义宽泛,几乎囊括了正确性、健壮性。
只要人们发现系统有毛病,便归结为可靠性差。
从专业角度讲,这种说法是不对的,
可是我们并不能要求所有的人都准确地把握质量属性的含义。
有必要搞清楚这两个容易混淆的概念。
- 故障是在经过日积月累,满足了一定的条件之后才出现的。
- 故障通常都是不可预料的、灾难性的。
在《现代英汉词典》里,“故障(Fault)”一词的定义是:
使设备、部件或元件不能按所要求的方式运行的一种意外情况,可能是物理的也可能是逻辑的。 那些潜伏在代码中的错误往往是不明显的,
之所以在测试的时候没有暴露,
是因为测试时的环境和条件不足以使之暴露,
更何况我们无法对代码进行最彻底的测试。
由此可见,故障是在经过日积月累,满足了一定的条件之后才出现的。
“错误”的含义要广泛得多
一般说来,程序错误是可以预料的,
因此可以预设错误处理程序,
运行时这些错误一旦发生,
就可以调用错误处理程序把它干掉,
程序还可以继续运行。
因此,错误的结果一般来说不是灾难性的。
语法错误、语义错误、文件打开失败、动态存储分配失败等
性能性能通常是指软件的“时间—空间”效率,而不仅是指软件的运行速度。
人们总希望软件的运行速度快些,并且占用资源少些。
旧社会地主就是这么对待长工的:干活要快点,吃得要少点。
程序员可以通过优化数据结构、算法和代码来提高软件的性能。
算法复杂度分析是很好的方法,可以达到“未卜先知”的功效。
性能优化的目标是“既要马儿跑得快,又要马儿吃得少”,关键任务是找出限制性能的“瓶颈”,不要在无关痛痒的地方瞎忙活。
例如,在大学里当教师,光靠卖力气地讲课或者埋头做实验,职称是升不快的。
有些人找到了突破口,一年之内“造”几十篇文章,争取破格升副教授、教授。在学术上走捷径,这类“学者”的质量真让人担忧。
性能优化就好像从海绵里挤水一样,你不挤,水就不出来,你越挤海绵越干。
有些程序员认为现在的计算机不仅速度越来越快,而且内存越来越大,因此软件性能优化的必要性下降了。
这种看法是不对的,殊不知随着机器的升级,软件系统也越来越庞大和复杂了,性能优化仍然大有必要。
最具有代表性的是三维游戏软件,
如《Delta Force》、《古墓丽影》、《反恐精英》等,如果不对软件(关键是游戏引擎)做精益求精的优化,
要想在一台普通的PC上顺畅地玩游戏是不太可能的。
易用性是指用户使用软件的容易程度。
现代人的生活节奏快,干什么事都可能想图个方便,所以把易用性作为重要的质量属性无可非议。
导致软件易用性差的根本原因是开发人员犯了“错位”的毛病:
他以为只要自己用起来方便,用户也一定会满意。
俗话说“王婆卖瓜,自卖自夸”。
当开发人员向用户展示软件时,常会得意地讲:“这个软件非常好用,我操作给你看,……是很好用吧!
”软件的易用性要让用户来评价。
如果用户觉得软件很难用,
开发人员不要有逆反心理:哪里找来的笨蛋!
其实不是用户笨,是自己开发的软件太笨了。
当用户真的感到软件很好用时,一股温暖的感觉就会油然而生,
于是就会用“界面友好”、“方便易用”等词来夸奖软件的易用性。
清晰性清晰意味着工作成果易读、易理解,这个质量属性表达了人们的一种质朴的愿望
开发人员只有在自己思路清晰的时候才可能写出让别人易读、易理解的程序和文档。
可理解的东西通常是简洁的。
一个原始问题可能很复杂,但高水平的人就能够把软件系统设计得很简洁。
如果软件系统臃肿不堪,它迟早会出问题。
所以简洁是人们对工作“精益求精”的结果,而不是潦草应付的结果。
让我花钱买它或者用一个东西,总得让我看明白它是什么东西。
我小时候的一个伙伴在读中学时就因搞不明白电荷为什么还要分“正”和“负”,
觉得很烦恼,便早早地辍学当了工人。
在生活中,与简洁对立的是“啰 唆”。
废话大师有句名言:“如 果我令你过于轻松地明白了,那你一定是误解了我的意思。”
中国小说中最“婆婆妈妈”的男人是唐僧。
有一项民意调查:如果世上只有唐僧、孙悟空、猪八戒和沙僧这四类男人,你要嫁给哪一类?
请列出优先级。调查结果表明,现代女性毫不例外地把唐僧摆在最后。
很多人在读研究生时有一种奇怪的体会:
如果把文章写得很简洁,让人很容易理解,投稿往往中不了,
只有加上一些玄乎的东西,把本来简单的东西弄成复杂的,才会增加投稿的命中率。
虽然靠这种做法可能有效,可千万不要把此“经验”应用到产品的开发中!
这里的安全性是指信息安全,英文是Security而不是Safety。
安全性是指防止系统被非法入侵的能力,既属于技术问题又属于管理问题。
信息安全是一门比较深奥的学问,其发展是建立在正义与邪恶的斗争之上的。
这世界似乎不存在绝对安全的系统,连美国军方的系统都频频遭黑客入侵。
如今全球黑客泛滥,真是“道高一尺,魔高一丈”啊!
对于大多数软件产品而言,杜绝非法入侵既不可能也没有必要。
因为开发商和客户愿意为提高安全性而投入的资金是有限的,他们要考虑值不值得。
究竟什么样的安全性是令人满意的呢?
一般地,如果黑客为非法入侵花费的代价(考虑时间、费用、风险等多种因素)高于得到的好处,
那么这样的系统就可以认为是安全的。
可扩展性反映了软件适应“变化”的能力。
在软件开发过程中,“变化”是司空见惯的事情,如需求、设计的变化,算法的改进、程序的变化等。
由于软件是“软”的,是否它天生就容易修改以适应“变化”?
关键要看软件的规模和复杂性。
如果软件规模很小,问题很简单,
那么修改起来的确比较容易,这时就无所谓“可扩展性”了。
要是软件的代码只有100行,那么“软件工程”也就用不着了。
如果软件规模很大,问题很复杂,倘若软件的可扩展性不好,
那么该软件就像用卡片造成的房子,抽出或者塞进去一张卡片都有可能使房子倒塌。
可扩展性是系统设计阶段重点考虑的质量属性。
兼容性是指两个或两个以上的软件相互交换信息的能力。
由于软件不是在“真空”里应用的,它需要具备与其他软件交互的能力。
ps: 早期word 是去兼容 wps 获取市场的
如果两个字处理软件的文件格式兼容,
那么它们都可以操作对方的文件,这种能力对用户很有好处。
国内金山公司开发的字处理软件WPS就可以操作Word文件。
兼容性的商业规则是:弱者设法与强者兼容,否则无容身之地;
强者应当避免被兼容,否则市场将被瓜分。
如果你经常看香港拍的“黑帮”影片,你就很容易明白这个道理。
所以WPS一定要与Word兼容,否则活不下去。
但是Word绝对不会与WPS兼容,除非WPS在中国称老大。
可移植性软件的可移植性指的是软件不经修改或稍加修改就可以运行于不同软硬件环境(CPU、OS和编译器)的能力,
主要体现为代码的可移植性。
编程语言越低级,用它编写的程序越难移植,反之则越容易。
这是因为,不同的硬件体系结构(如Intel CPU和SPARC CPU)使用不同的指令集和字长,
而OS和编译器可以屏蔽这种差异,所以高级语言的可移植性更好。
C++/C是一种中级语言,因为它具有灵活的“位操作”能力(因此具有硬件操作能力),
而且可以直接嵌入汇编代码。
但是C++/C并不依赖于特定的硬件,因此比汇编语言可移植性好。
Java是一种高级语言,Java程序号称“一次编译,到处运行”,具有100%的可移植性。
为了提高Java程序的性能,最新的Java标准允许人们使用一些与平台相关的优化技术,
这样优化后的Java程序虽然不能“一次编译,到处运行”,仍然能够“一次编程,到处编译”。
一般地,软件设计时应该将“设备相关程序”与“设备无关程序”分开,
将“功能模块”与“用户界面”分开,这样可以提高可移植性。
企业开发产品的目的是赚钱,为了使利润最大化,
人们希望软件开发工作“做得好、做得快,并且少花钱”。
用软件工程的术语来讲,即“提高质量、提高生产率,并且降低成本”。
古代哲学家曾为“鱼与熊掌不可兼得”的问题费尽心思,
我们现在却梦想鱼、熊掌、美酒三者兼得,现代人的欲望真是无止境啊。
让我们先谈谈质量、生产率和成本之间的关系。
跳过一大段介绍降低成本重要性的废话.
跳过一大段介绍软件工程无法满足需求从而逐渐转变为软件过程的描述 CMM和CMMI的描述.
过程就是人们使用相应的方法、规程、技术、工具等将原始材料(输入)转化成用户需要的产品(输出)。
过程的3个基本要素是:人、方法与规程、技术与工具,如图1-1所示。
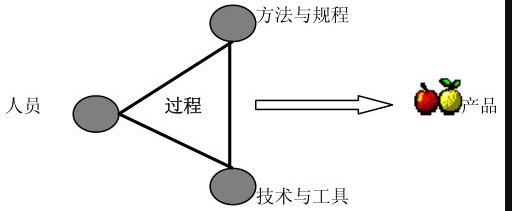
可以把过程比喻为3条腿的桌子,要使桌子平稳,这3条腿必须协调好。
从图1-1可知,过程与产品存在因果关系,即好的过程才能得到好的产品,
而差的过程只会得到差的产品。这个道理很朴实,但是很多人并未理解或者理解了却不执行。
毕竟我们销售的是产品,而非过程。
人们常常只把眼光盯在产品上,而忘了过程的重要性。
例如,领导对员工们下达命令时总强调:“我不管你们如何做,反正时间一到,你们就得交付产品。
”其实这是一句因果关系颠倒了的话,却在业界普遍存在。
在过程混乱的企业里,一批人累死累活地做完产品后,马上又因质量问题被折腾得焦头烂额。
这种现象反反复复地发生,让人疲惫不堪。
怎么办?长痛不如短痛,应该下决心,舍得花精力与金钱去改进软件过程能力。
CMM(Capability Maturity Model)是用于衡量软件过程能力的事实上的标准,
同时也是目前软件过程改进最好的参考标准。
CMM是由美国卡内基—梅隆大学(Carnegie-Mellon)
软件工程研究所(Software Engineering Institute, SEI)研制的,
其发展简史如下
✧ CMM 1.0于1991年制定。✧ CMM 1.1于1993年发布,该版本应用最广泛。
✧ CMM 2.0草案于1997年制定(未广泛应用)。
✧ 到2000年,CMM演化成为CMMI(Capability Maturity Model Integration),CMM 2.0成为CMMI 1.0的主要组成部分。
✧ CMMI-SE/SW 1.1(CMMI for System Engineering and Software Engineering)于2002年1月正式推出。
CMM将软件过程能力分为5个级别,最低为1级,最高为5级。
目前国内只有几家IT企业达到了CMM 2级或CMM 3级。
鉴于CMM已经被美国、印度软件业广为采纳,并且取得了卓著成效,近两年来国内兴起了CMM热潮。
CMM受欢迎的程度远远超过了ISO同类标准。
国内IT企业采用CMM的目的大体有两种:
(1)主要想提高企业的软件过程能力,但并不关心CMM评估。
(2)既要提高企业的软件过程能力,又想通过CMM评估来提升企业的威望与知名度。
出于第一种考虑的企业占绝大多数,它们主要是一些中小型IT企业。
出于第二种考虑的一般是实力雄厚的大型IT企业。
无论是哪类IT企业,它们在实施CMM时遇到的共性问题是“费用高、难度大、见效慢”。
企业做一次比较完整的CMM 2~3级咨询和评估大约要花费60万元~100万元。
然而CMM咨询师只能起到“参谋”的作用,解决实际问题还得靠自己。
企业要组建软件工程过程小组(Software Engineering Process Group, SEPG)
专门从事CMM研究与推广工作,SEPG的成本并不比咨询费低。
如果企业再购买一些昂贵的软件工程工具(如Rational的产品),那么总成本会更高。
即使企业舍得花钱,也不意味着就能够轻易地提高软件过程能力。
目前国内通过CMM 2-3级评估的企业屈指可数,而这些企业的实际能力也没有宣传的那么好。
因为参加CMM评估的项目都是精心准备的,个别项目或者事业部通过了CMM评估并不意味着整个企业达到了那个水平,
这里面的水分相当大。曾经有一段时间,IT人士经常争论“CMM好不好”、
“值不值得推广CMM”等话题。
现在业界关注的焦点则是“企业如何以比较低的代价有效地提高软件过程能力”,
攻克这个难题必将产生巨大的经济效益和社会效益。
一般地,为了真正提高软件过程能力,企业至少要做3件最重要的事情:
(1)制定适合于本企业的软件过程规范。
(2)对员工们进行培训,指导他们依据规范来开发产品。
(3)购买或者开发一些软件工程和项目管理工具,提高员工们的工作效率。
本书作者和合作者根据上述需求,研制了一套
“软件过程改进解决方案”(Software Process Improvement Solution, SPIS)。
SPIS的主要组成部分如下:
✧ 基于CMMI 3级的软件过程改进方法与规范,命名为“精简并行过程”(SPP)。
✧ 一系列培训教材,包括软件工程、项目管理、高质量C++/Java编程等,本书即为其中之一。
✧ 基于Web的集成化项目管理工具,包括项目规划、项目监控、质量管理、配置管理、需求管理等功能,命名为Future。
跳过背景介绍,以及软件模型的介绍,直接进入正题.
SPP模型把产品生命周期划分为6个阶段:
✧ 产品概念阶段,记为PH0。
✧ 产品定义阶段,记为PH1。
✧ 产品开发阶段,记为PH2。
✧ 产品验证阶段,记为PH3。
✧ 用户验收阶段,记为PH4。
✧ 产品维护阶段,记为PH5。
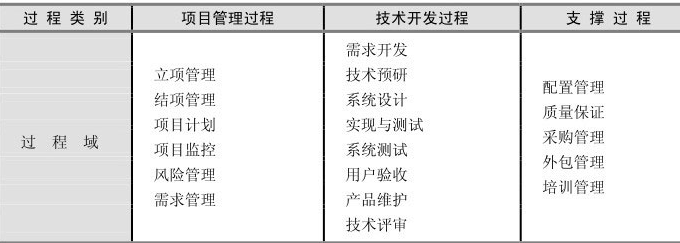
在SPP模型中,一个项目从PH0到PH5共经历19个过程域(Process Area),
它们被划分为3大类过程,如表1-2所示。其中项目管理过程含6个过程域,技术开发过程含8个过程域,支撑过程含5个过程域。
(1)模型直观。
SPP模型是三层结构,上层是项目管理过程的集合,
中层是技术开发过程的集合,下层是支撑过程的集合。
这种模型很直观,高级经理、项目经理、开发人员、
质量保证员等根据SPP模型就很容易知道自己“应该在什么时候做什么事情,
以及按照什么规范去做事情”。SPP模型有助于使各个过程的活动有条不紊地开展。
(2)便于用户裁剪SPP模型。
项目管理过程和支撑过程对绝大多数软件产品开发而言都是适用的。
需求开发、技术预研、系统设计、编程、测试、技术评审、维护都是技术开发过程中必不可少的环节,
用户可以根据产品的特征确定最合适的开发模型(如瀑布模型、快速原型模型、迭代模型等)。
(3)便于用户扩充SPP模型。
如果产品同时涉及软件、硬件开发的话,
可将产品生命周期、软件开发过程和硬件开发过程集成起来
复用就是指“利用现成的东西”。
被复用的对象可以是有形的物体,也可以是无形的知识成果。
复用不是人类懒惰的表现,而是智慧的表现。
因为人类总是在继承了前人的成果,不断加以利用、改进或创新后才会进步。
分而治之是指把一个复杂的问题分解成若干个简单的问题,然后逐个解决。
这种朴素的思想来源于人们的生活和工作经验,完全适合于技术领域。
软件的“分而治之”应该着重考虑:复杂问题分解后,每个问题能否用程序实现?
所有程序能否最终集成为一个软件系统并有效解决原始的复杂问题?
质量保证(Quality Assurance, QA)的目的是提供一种有效的人员组织形式和管理方法,
通过客观地检查和监控“过程质量”与“产品质量”,从而实现持续地改进质量。
质量保证是一种有计划的、贯穿于整个产品生命周期的质量管理方法。
有最好的编程语言吗?
编程是一门艺术吗?
编程时应该多使用技巧吗?
换更快的计算机还是换更快的算法?
错误是否应该分等级
一些错误的观念
软件质量属性之间并非完全独立的,而是互相交织、互相影响的
。因此,程序设计中要同时兼顾几个质量属性,使程序达到整体最优。
要把质量属性记在心,这样才能在程序设计时一次性地编写出高质量的、错误较少的代码来,
同时也可以减轻查错和调试的负担。经典的软件工程书籍厚得像砖头,
或让人望而却步,或让人看了心事重重。
请宽恕作者的幼稚,本章试图用聊天、说理的方式来解释软件工程的道理。
软件工程的观念、方法和规范都是朴实无华的,平凡之人 可领会,但只有实实在在地用起来才有价值。
我们不可以把软件工程方法看成是诸亮的 囊妙计—在出了问题之后才打开看看,
而应该事先预料将要出现的问题,控制每个实践环节,防患于未然。
研究软件工程永远做不到像理论家那样潇洒:定理证明了,就完事儿。
编程语言大事 Ada 第一个编程语言 C/C++ 发展历史 Java 发展历史
编程语言发展到今天,已经越来越平台化。
掌握一门编程语言,不仅要求懂得语法,
还要能熟练使用该语言的集成开发环境和相应的库函数。
世上不存在最好的编程语言,每一种语言都有其优点和缺点,
能够很好地解决应用问题的编程语言就是好语言。
开发人员应当根据待开发产品的特征,选择业界推荐的并且是自己擅长的编程语言来开发软件。
语言之间存在一定的相似性,学好一门语言后再学其他语言就容易得多,
所以精通一门编程语言将使你长期受益。
程序设计语言实际上就是一套规范的集合,
主要包括该语言使用的字符集、直接和间接支持的数据类型集合、
运算符集合、关键字集合、指令集合、语法规则,
以及对特定构造的支持,例如,函数(过程)的定义、
抽象数据类型的定义、继承、模板、异常处理等。
这些内容就是一个语言的构造或者说特征集。
可见,语法只是语言的一部分,
它指导程序员如何把语言的各种构造组合起来形成一系列可以解决实际问题的可执行命令,
这就是程序。
一种语言对于它的各种构造的支持是通过各种关键字集合及其语法规则来实现的。
就拿标准C语言来说,它支持函数设计,
但是语言本身并没有提供任何现成的函数可以直接调用(你可能认为sizeof是一个函数,其实它是一个运算符)。
它支持用户定义struct、union、enum等,
但是它本身并没有提供任何具体的struct、union、enum类型供程序员使用。
有人会问,我们学习C语言的时候总是首先学习它的“格式化I/O”,
以便看到自己程序的运行成果,难道“格式化I/O”不是C语言的组成部分吗?
确实不是!
标准C语言没有提供I/O的实现,只是定义了标准的I/O函数接口,
所有的I/O工作都是通过库函数来完成的,在这一点上它不同于BASIC。
标准C++语言继承了C的I/O库函数接口,并且重新定义了自己的面向对象的I/O系统。
I/O系统并不是C++/C语言本身的组成部分,函数库和类库也不是它们的组成部分
学习一门程序设计语言,并不需要掌握其全部的语法,关键是要学习使用语言来解决实际问题的方法。
例如,C语言的格式化I/O非常复杂,有不少程序员努力去记住那么多的格式控制符号,其实完全没有必要!
还有C运算符的优先级和结合率,也没有必要把它们完全搞清楚,
遇到这种问题时只需要按照自己要求的计算顺序多使用“()”就可以解决。
很多人在学习程序设计语言时常常沉迷于语法,这是学习的误区!
如果记不住很多语法细节,你可以查阅手册,但是程序设计的道理、解决实际问题的方法是没有地方可查阅的。
如果你所掌握的语法和程序设计方法能够高效地解决实际工作中的各种问题,
那么表明你已经掌握了这门语言。
语言实现就是具体地实现一种语言的各种特征并支持特定编程模式的技术和工具。
一般地讲,编程语言的实现就是编译器(compiler)和连接器(linker)(编译—连接模式)
或者解释器(interpreter)(解释模式)的实现,
即用来分析你的源代码并生成最终的可执行机器指令集合的技术和工具,
以及一套标准库实现。
语言最终要表现为某个或某些具体的实现版本,但是语言实现并不就是语言本身,
因为对于那些允许扩展的标准化语言,它们的实现往往会对那些可扩展的部分进行必要的修改和扩展,
这就产生了方言(dialect)。
C++/C就是允许扩展的语言,
即它的标准规范文本中定义和说明了许多实现相关的及平台相关的特征细节,
这就要求语言实现根据具体的平台环境和实现技术来修改或定义自己的解决办法。
比如在C++/C标准规范中,程序的行为就有一种“实现定义的行为(即依赖于实现的行为)”,
就是程序在运行时某些情况下的行为要靠具体的语言实现来定义,
而标准规范不会强加定义。C++/C语言有许多的方言,
如Turbo C++/C、Borland C++/C、Microsoft C++/C、GNU C++/C等,
都是C++/C不同的实现版本。
所以,要根据你所使用的C++/C语言实现来确定那些“实现定义的行为”的具体含义。
另外,语言标准可能会要求实现提供可用的标准化库(Standard Library)。
库增加了语言的灵活性和可扩展性。各种库的实现方法可能不同,
但是其接口必须是标准化的(一致的),
否则会给用户带来不便。
编译器开发商在提供语言实现的同时可能还会提供集成开发环境(IDE),
不论是可视化的还是非可视化的IDE,其目的都是帮助程序员提高编程效率。
一个具体的语言实现必须支持语言规范所定义的核心特征,
除此之外的特征和对核心特征的修改都属于扩展
Microsoft C++/C就分别对ANSI/ISO C++/C进行了必要的扩展,
具体表现在关键字、类型转换、单行注释、变长参数列表、作用域规则及增加的编译器选项等方面(详见其编译器文档)。
此外,随着技术的发展,解决了一些问题,而到了需要对语言本身进行修订的时候,
#### #e 语言的扩展与修订
例如,增加一些新的特征和删除一些过时的特征,就需要对语言的核心进行扩展,
当然语言的实现也要做出相应的修订。
例如,C++希望将来能够增加对象持久性、并行处理等特征,而这些恐怕无法通过库来实现,
必须对语言的核心特征进行必要的扩展才能解决,但是现在的技术水平还无法完成这个任务。
由于存在着“依赖于实现的行为”等诸多因素,不同语言实现之间可能并不完全兼容。
这种不兼容包括代码的不兼容、特征实现的不兼容、库的不兼容、编译器和连接器的不兼容,
以及它们生成的中间文件的不兼容(即二进制不兼容),等等。
就拿标识符重命名(Name-Mangling)方案来说,
Microsoft C++采用的方案就和Borland C++的不同
(C++标准并没有规定这些,但是C标准规定了),
从而导致一方编译生成的目标文件(.obj)拿到另一方的连接器上无法连接的问题,
还有不能同时使用不同实现的库等问题。
虽然一种语言可能存在不同的实现,但是学好标准语言本身无疑是最重要的!
过去经常听说“某某人在钻研Visual C++”,
我不知道他是在学习C++语言还是在学习Visual C++的IDE和MFC或者兼而有之。
有些人甚至错误地认为学会使用Visual C++ IDE就是学会了C++语言。这又是一个误区!
首先掌握语言的特征及其使用方法,再学习具体的语言实现才是语言学习的正道!
C++/C程序的可执行部分都是由函数组成的,
main()就是所有程序中都应该提供的一个默认全局函数——
主函数——所有的C++/C程序都应该从函数main()开始执行。
但是语言实现本身并不提供main()的实现(它也不是一个库函数),
并且具体的语言实现环境可以决定是否用main()函数来作为用户应用程序的启动函数,
这是标准赋予语言实现的权利(又是一个“实现定义的行为”☺)。
虽然main不是C++/C的保留字
(因此你可以在其他地方使用main这个名字,比如作为类、名字空间或者成员函数等的名字),
但是你也不可以修改main()函数的名字。如果修改了main()的名字,
比如改为mymain,连接器就会报告类似的连接时错误:“unresolved external symbol _main”。
这是因为C++/C语言实现有一个启动函数,
main()可以看作是一个回调函数。
main()由我们来实现,但是不需要我们提供它的原型,
因为我们并不能在自己的程序中调用它,这又和普通的回调函数有所不同。
例如,MS C++/C应用程序的启动函数为mainCRTStartup()或者WinMainCRT-Startup(),
同时在该函数的末尾调用了main()或者WinMain(),
然后以它们的返回值为参数调用库函数exit(),
因此也就默认了main()应该作为它的连接对象,
如果找不到这样一个函数定义,自然会报错了。
基于应用程序框架(Application Framework,如MFC)生成的源代码中往往找不到main(),
这并不是说这样的程序中就不需要main(),而是应用程序框架把main()的实现隐藏起来了,
并且它的实现具有固定的模式,所以不需要程序员来编写。
在应用程序的连接阶段,框架会将包含main()实现的library加进来一起连接。
在嵌入式框架arduino中,就没有main函数的影子.
开发者只需要编写 setup 与 loop 中的内容即可实现一个简单的程序
main应该返回int,但是具体返回什么类型可以被[实现]扩展- 所有实现都必须至少允许两种形式的
main 无参数形式
int main (){ /*....*/}有参数形式
并允许实现再参数
argv后面增加任何需要的也是可选的参数int main (int argc, char *argv[])
比如MS C++/C允许main()返回void,
以及增加第三个参数char* env[]等。
读者可参考编译器的帮助文档,以了解当前的编译器支持怎样的扩展形式。
当main()返回int类型时,不同的返回值具有不同的含义。
当返回0时,表示程序正常结束;
返回任何非0值表示错误或者非正常退出。
exit()用main()的返回值作为返回操作系统的代码,
以指示程序执行的结果(当然你也可以在main()或其他函数内直接调用exit()来结束程序)。
(1)不能重载。
(2)不能内联。
(3)不能定义为静态的。
(4)不能取其地址。
(5)不能由用户自己调用。
我们可能希望可执行程序具有处理命令行参数的能力,
如常用的“dir X:\document /p /w”等DOS或UNIX命令
命令行参数是由启动程序截获并打包成字符串数组后传递给main()的一个形参argv,
包括命令字(即可执行文件名称)在内的所有参数的个数则被传递给形参argc。
下面是一个dos时期的文件拷贝示例代码
用法示例
mycopy C:\file.txt C:\newFile.txt
示例代码
// mycopy.c : copy file to a specified destination file.
#include <stdio.h>
int main(int argCount, char* argValue[])
{
FILE *srcFile = 0, *destFile = 0;
int ch = 0;
if (argCount != 3) {
printf("Usage: %s src-file-name dest-file-name\n", argValue[0]);
} else {
if (( srcFile = fopen(argValue[1], "r")) == 0) {
printf("Can not open source file \"%s\" !", argValue[1]);
} else {
if ((destFile = fopen( argValue[2], "w")) == 0) {
printf("Can not open destination file \"%s\"!", argValue[2]);
fclose(srcFile); /*!!!*/
} else {
while((ch = fgetc(srcFile)) != EOF) fputc(ch, destFile);
printf("Successful to copy a file!\n");
fclose(srcFile); /*!!!*/
fclose(destFile); /*!!!*/
return 0; /*!!!*/
}
}
}
return 1;
}
// 用法示例:
mycopy C:\file1.dat C:\newfile.dat
C和C++语言实现都会按照特定的规则把用户(指程序员)
定义的标识符(各种函数、变量、类型及名字空间等)转换为相应的内部名称。
当然,这些内部名称的命名方法还与用户为它们指定的连接规范有关,
比如使用C的连接规范,则main的内部名称就是_main。
用于更好地区分函数
不同的实现会采取不同的Name-Mangling方案
在C语言中,所有函数不是局部于编译单元(文件作用域)的static函数,
就是具有extern连接类型和global作用域的全局函数,
因此除了两个分别位于不同编译单元中的static函数可以同名外,
全局函数是不能同名的;全局变量也是同样的道理。
其原因是C语言采用了一种极其简单的函数名称区分规则:
仅在所有函数名的前面添加前缀“_”,
从唯一识别函数的作用上来说,
实际上和不添加前缀没什么不同。
但是,C++语言允许用户在不同的作用域中定义同名的函数、类型、变量等,
这些作用域不仅限于编译单元,还包括class、struct、union、namespace等,
甚至在同一个作用域中也可定义同名的函数,即重载函数。
那么编译器和连接器如何区分这些同名且又都会在同一个编译单元中被引用的程序元素呢?
编译器如何识别下面的foo是调用哪个函数呢?
Sample_1 a;
Sample_2 b;
a.foo(“aaa”);
a.foo(100);
b.foo(“bbb”);
b.foo(false);
在连接器看来,所有函数都是全局函数,
能够用来区分不同函数调用的除了作用域外就是函数名称了。
但是,上面的调用显然都是合理合法的。
因此,如果不对它们进行重命名,就会导致连接二义性。
在C++中,重命名称为“Name-Mangling”(名字修饰或名字改编)
例如,在它们的前面分别添加所属各级作用域的名称(class、namespace等)
及重载函数的经过编码的参数信息(参数类型和个数等)作为前缀或者后缀,
产生全局名字
Sample_1_foo@pch@1、
Sample_1_foo@int@1、
Sample_2_foo@pch@1
和Sample_2_foo@int@1,
这样就可以区分了。
关于这方面更详细的信息请参考Lippman的
《Inside The C++ Object Model》相关章节,
你也可以从MS C++/C编译器输出的
MAP文件了解一下它所Mangling出来的函数的内部名称。
- 不同
语言联合开发共享接口 - 通用连接规范
extern "C" - 声明与实现应当同一规范
extern "C" void WinMainCRTStartup();
extern "C" const CLSID CLSID_DataConverter;
extern "C" struct Student{……};
extern "C" Student g_Student;
#ifdef __cplusplus
extern "C" {
#endif
const int MAX_AGE = 200;
#pragma pack(push, 4)
typedef struct _Person
{
char *m_Name;
int m_Age;
} Person, *PersonPtr;
#pragma pack(pop)
Person g_Me;
int __cdecl memcmp(const void*,const void*,size_t);
void* __cdecl memcpy(void*,const void*,size_t);
void* __cdecl memset(void*,int,size_t);
#ifdef __cplusplus
}
#endif
如果当前使用的是C++编译器,
并且使用了extern“C”来限定一段代码的连接规范,
但是又想令其中某行或某段代码保持C++的连接规范,
则可以编写如下代码(具体要看你的编译器是否支持extern“C++”)
#ifdef __cplusplus
extern "C" {
#endif
const int MAX_AGE = 200;
#pragma pack(push, 4)
typedef struct _Person
{
char *m_Name;
int m_Age;
} Person, *PersonPtr;
#pragma pack(pop)
Person g_Me;
#if _SUPPORT_EXTERN_CPP_
extern “C++” {
#endif
int __cdecl memcmp(const void*,const void*,size_t);
void* __cdecl memcpy(void*,const void*,size_t);
#if _SUPPORT_EXTERN_CPP_
}
#endif
void* __cdecl memset(void*,int,size_t);
#ifdef __cplusplus
}
#endif
这段我实在看不明白写的是什么意思,每个字我都认识
如果在某个声明中指定了某个标识符的连接规范为extern“C”,
那么也要为其对应的定义指定extern“C”连接规范,如下所示:
#ifdef __cplusplus
extern "C" {
#endif
int __cdecl memcmp(const void*,const void*,size_t); // 声明
#ifdef __cplusplus
}
#endif
#ifdef __cplusplus
extern "C" {
#endif
int __cdecl memcmp(const void*p,const void*a,size_t len)
{
…… // 功能实现
}
#ifdef __cplusplus
}
#endif
但是对COM接口方法
(Interface Methods,Interface中的pure virtual functions)
使用的C复合数据类型来说(它们也是COM对象接口的组成部分),
是否采用统一的连接规范,
对COM对象及组件的二进制数据兼容性和可移植性都没有影响。
因为即使接口两端(COM接口实现端和接口调用端)
对接口数据类型的内部命名不同,
只要它们使用了一致的成员对齐和排列方式、一致的调用规范、
一致的virtual function实现方式,
总之就是一致的C++对象模型,
并且保证COM组件升级时不改变原来的接口和数据类型定义,
则所有方法的运行时绑定和参数传递都不会存在问题
(所有方法的调用都被转换为通过对象指针对vptr和vtable以及函数指针的访问和调用,
这种间接性不再需要任何方法名即函数名的参与,
而接口名和方法名只是为了让客户端的代码能够顺利通过编译,
但是连接时就全部不再需要了)。
变量就是用来保存数据的程序元素,它是内存单元的别名,
取一个变量的值就是读取其内存单元中存放的值,
而写一个变量就是把值写入到它代表的内存单元中
全局变量的声明和定义应当放在源文件的开头位置。
在C++/C中,全局变量(extern或static的)存放在程序的静态数据区中
如果你没有明确地给全局变量提供初始值,编译器会自动地将0转换为所需要的类型来初始化它们
一个编译单元中定义的全局变量的初始值不要依赖定义于另一个编译单元中的全局变量的初始值
编译器和连接器可以决定同一个编译单元中定义的全局变量的
初始化顺序保持与它们定义的先后顺序一致,
但是却无法决定当两个编译单元连接在一起时
哪一个的全局变量的初始化先于另一个编译单元的全局变量的初始化。
也就是说,这一次编译连接和下一次编译连接很可能使
不同编译单元之间的全局变量的初始化顺序发生改变。
一般来说,一个C++/C程序不可能不使用C运行时库,
即使你没有显式地调用其中的函数也可能间接地调用,
只是我们平时没有在意罢了。
例如,启动函数、I/O系统函数、存储管理、RTTI、动态决议、
动态链接库(DLL)等都会调用C运行时库中的函数。
我们在每一个程序开头包含的stdio.h头文件中的许多I/O函数就是它的一部分。
C运行时库有多线程版和单线程版,
开发多线程应用程序时应该使用多线程版本的库,
仅在开发单线程程序时才使用单线程版本。
另外,同一软件的不同模块最好使用一致的运行时库,否则会出现连接问题。
我们把编译预处理器、编译器和连接器工作的阶段合称“编译时”。
语言中有些构造仅在编译时起作用,而有些构造则是在“运行时”起作用的,
分清楚这些构造对于程序设计很重要。
例如,预编译伪指令、类(型)定义、外部对象声明、函数原型、
标识符、各种修饰符号(const、static等)
及类成员的访问说明符(public、private、protected)
和连接规范、调用规范等,
仅在编译器进行语法检查、语义检查和生成目标文件(.obj或.o文件)
及连接的时候起作用的,在可执行程序中不存在这些东西。
容器越界访问、虚函数动态决议、函数动态连接、动态内存分配、
异常处理和RTTI等则是在运行时才会出现和发挥作用的,
因此运行时出现的程序问题大多与这些构造有关。
下面代码在编译时绝对没有问题,但是运行时会出现错误
int *pInt = new int[10];
pInt+=100; // 越界,但是还没有形成越界访问
cout<<*pInt<<endl; // 越界访问!可能行,也可能不行!
*pInt=1000; // 越界访问!即使偶尔不出问题,但不能确保永远不出问题!
下述代码在编译时没有问题,在运行时也不会出现错误,但是违背了private的用意。
class Base {
public:
virtual void Say(){ cout<< "Base::Say() was invoked!\n"; }
};
class Derived : public Base {
private: // 改变访问权限,合法但不是好风格!
virtual void Say(){cout<<“Derived::Say()was invoked!\n”;}
};
// 测试
Base *p = new Derived;
p->Say(); // 输出:Derived::Say()was invoked!
// 出乎意料地绑定到了一个private函数身上!
我们在程序设计时就要对运行时的行为有所预见,
通过编译连接的程序在运行时不见得就是正确的。
虽然你能够一时“欺骗”编译器(因为编译器还不够聪明),
但是由此造成的后果要你自己来承担。
这里我们引用Bjarne Stroustrup的一段话来说明这一问题:
“C++的访问控制策略是为了防止意外事件而不是防止对编译器的故意欺骗。
任何程序设计语言,只要它支持对原始存储器的直接访问(如C++的指针),
就会使数据处于一种开放的状态,
使所有有意按照某种违反数据项原有类型安全规则所描述的方式去触动它的企图都能够实现,
除非该数据项受到操作系统的直接保护。”
语言实现和开发环境支持的独立编译技术并非语言本身所规定的。
每一个源代码文件(源文件及其递归包含的所有头文件展开)
就是一个最小的编译单元,
每一个编译单元可以独立编译而不需要知道其他编译单元的存在及其编译结果。
例如,一个编译单元在单独编译的时候根本无法知道
另一个编译单元在编译的时候是否已经定义了一个同名的extern全局变量或全局函数,
所以每个编译单元都能够通过编译,
但是如果另一个编译单元也定义了同名的extern全局变量或全局函数,
那么将两个目标文件连接到一起的时候就会出错。
独立编译技术最大的好处就是公开接口而隐藏实现,
并可以创建预定义的二进制可重用程序库(函数库、类库、组件库等),
在需要的时候用连接器将用户代码与库代码连接成可执行程序。
另一方面,独立编译技术可以大大减少代码修改后重新编译的时间。